Note
Go to the end to download the full example code.
Walk through intermediate outputs¶
We reuse the example Convert a pipeline with ColumnTransformer and walk through intermediates outputs. It is very likely a converted model gives different outputs or fails due to a custom converter which is not correctly implemented. One option is to look into the output of every node of the ONNX graph.
Create and train a complex pipeline¶
We reuse the pipeline implemented in example
Column Transformer with Mixed Types.
There is one change because
ONNX-ML Imputer
does not handle string type. This cannot be part of the final ONNX pipeline
and must be removed. Look for comment starting with --- below.
import skl2onnx
import onnx
import sklearn
import matplotlib.pyplot as plt
import os
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
from skl2onnx.helpers.onnx_helper import select_model_inputs_outputs
from skl2onnx.helpers.onnx_helper import save_onnx_model
from skl2onnx.helpers.onnx_helper import enumerate_model_node_outputs
from skl2onnx.helpers.onnx_helper import load_onnx_model
import numpy
import onnxruntime as rt
from skl2onnx import convert_sklearn
import pprint
from skl2onnx.common.data_types import (
FloatTensorType,
StringTensorType,
Int64TensorType,
)
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
titanic_url = (
"https://raw.githubusercontent.com/amueller/"
"scipy-2017-sklearn/091d371/notebooks/datasets/titanic3.csv"
)
data = pd.read_csv(titanic_url)
X = data.drop("survived", axis=1)
y = data["survived"]
# SimpleImputer on string is not available
# for string in ONNX-ML specifications.
# So we do it beforehand.
for cat in ["embarked", "sex", "pclass"]:
X[cat].fillna("missing", inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
numeric_features = ["age", "fare"]
numeric_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler())]
)
categorical_features = ["embarked", "sex", "pclass"]
categorical_transformer = Pipeline(
steps=[
# --- SimpleImputer is not available for strings in ONNX-ML specifications.
# ('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features),
]
)
clf = Pipeline(
steps=[
("preprocessor", preprocessor),
("classifier", LogisticRegression(solver="lbfgs")),
]
)
clf.fit(X_train, y_train)
/home/xadupre/github/sklearn-onnx/docs/examples/plot_intermediate_outputs.py:69: ChainedAssignmentError: A value is being set on a copy of a DataFrame or Series through chained assignment using an inplace method.
Such inplace method never works to update the original DataFrame or Series, because the intermediate object on which we are setting values always behaves as a copy (due to Copy-on-Write).
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' instead, to perform the operation inplace on the original object, or try to avoid an inplace operation using 'df[col] = df[col].method(value)'.
See the documentation for a more detailed explanation: https://pandas.pydata.org/pandas-docs/stable/user_guide/copy_on_write.html
X[cat].fillna("missing", inplace=True)
Define the inputs of the ONNX graph¶
sklearn-onnx does not know the features used to train the model but it needs to know which feature has which name. We simply reuse the dataframe column definition.
print(X_train.dtypes)
pclass int64
name str
sex str
age float64
sibsp int64
parch int64
ticket str
fare float64
cabin str
embarked str
boat str
body float64
home.dest str
dtype: object
After conversion.
def convert_dataframe_schema(df, drop=None):
inputs = []
for k, v in zip(df.columns, df.dtypes):
if drop is not None and k in drop:
continue
if v == "int64":
t = Int64TensorType([None, 1])
elif v == "float64":
t = FloatTensorType([None, 1])
else:
t = StringTensorType([None, 1])
inputs.append((k, t))
return inputs
inputs = convert_dataframe_schema(X_train)
pprint.pprint(inputs)
[('pclass', Int64TensorType(shape=[None, 1])),
('name', StringTensorType(shape=[None, 1])),
('sex', StringTensorType(shape=[None, 1])),
('age', FloatTensorType(shape=[None, 1])),
('sibsp', Int64TensorType(shape=[None, 1])),
('parch', Int64TensorType(shape=[None, 1])),
('ticket', StringTensorType(shape=[None, 1])),
('fare', FloatTensorType(shape=[None, 1])),
('cabin', StringTensorType(shape=[None, 1])),
('embarked', StringTensorType(shape=[None, 1])),
('boat', StringTensorType(shape=[None, 1])),
('body', FloatTensorType(shape=[None, 1])),
('home.dest', StringTensorType(shape=[None, 1]))]
Merging single column into vectors is not the most efficient way to compute the prediction. It could be done before converting the pipeline into a graph.
Convert the pipeline into ONNX¶
scikit-learn does implicit conversions when it can. sklearn-onnx does not. The ONNX version of OneHotEncoder must be applied on columns of the same type.
X_train["pclass"] = X_train["pclass"].astype(str)
X_test["pclass"] = X_test["pclass"].astype(str)
white_list = numeric_features + categorical_features
to_drop = [c for c in X_train.columns if c not in white_list]
inputs = convert_dataframe_schema(X_train, to_drop)
model_onnx = convert_sklearn(clf, "pipeline_titanic", inputs, target_opset=12)
# And save.
with open("pipeline_titanic.onnx", "wb") as f:
f.write(model_onnx.SerializeToString())
Compare the predictions¶
Final step, we need to ensure the converted model produces the same predictions, labels and probabilities. Let’s start with scikit-learn.
print("predict", clf.predict(X_test[:5]))
print("predict_proba", clf.predict_proba(X_test[:1]))
predict [1 0 0 0 0]
predict_proba [[0.31340714 0.68659286]]
Predictions with onnxruntime. We need to remove the dropped columns and to change the double vectors into float vectors as onnxruntime does not support double floats. onnxruntime does not accept dataframe. inputs must be given as a list of dictionary. Last detail, every column was described not really as a vector but as a matrix of one column which explains the last line with the reshape.
X_test2 = X_test.drop(to_drop, axis=1)
inputs = {c: X_test2[c].values for c in X_test2.columns}
for c in numeric_features:
inputs[c] = inputs[c].astype(np.float32)
for k in inputs:
inputs[k] = np.asarray(inputs[k]).reshape((inputs[k].shape[0], 1))
We are ready to run onnxruntime.
predict [1 0 0 0 0]
predict_proba [{0: 0.15586718916893005, 1: 0.8441327810287476}]
Compute intermediate outputs¶
Unfortunately, there is actually no way to ask onnxruntime to retrieve the output of intermediate nodes. We need to modifies the ONNX before it is given to onnxruntime. Let’s see first the list of intermediate output.
merged_columns
embarkedout
sexout
pclassout
concat_result
variable
variable2
variable1
transformed_column
label
probabilities
output_label
output_probability
Not that easy to tell which one is what as the ONNX has more operators than the original scikit-learn pipelines. The graph at Display the ONNX graph helps up to find the outputs of both numerical and textual pipeline: variable1, variable2. Let’s look into the numerical pipeline first.
num_onnx = select_model_inputs_outputs(model_onnx, "variable1")
save_onnx_model(num_onnx, "pipeline_titanic_numerical.onnx")
b'\x08\x07\x12\x08skl2onnx\x1a\x061.20.0"\x07ai.onnx(\x002\x00:\xcd\x03\n:\n\x03age\n\x04fare\x12\x0emerged_columns\x1a\x06Concat"\x06Concat*\x0b\n\x04axis\x18\x01\xa0\x01\x02:\x00\n}\n\x0emerged_columns\x12\x08variable\x1a\x07Imputer"\x07Imputer*#\n\x14imputed_value_floats=\x00\x00\xe0A=gDgA\xa0\x01\x06*\x1e\n\x14replaced_value_float\x15\x00\x00\xc0\x7f\xa0\x01\x01:\nai.onnx.ml\n^\n\x08variable\x12\tvariable1\x1a\x06Scaler"\x06Scaler*\x15\n\x06offset=\xd1\xe6\xeaA=}\xa3\x02B\xa0\x01\x06*\x14\n\x05scale=\xfei\xa0==\x1c:\xa3<\xa0\x01\x06:\nai.onnx.ml\x12\x10pipeline_titanic*\x1f\x08\x02\x10\x07:\x0b\xff\xff\xff\xff\xff\xff\xff\xff\xff\x01\tB\x0cshape_tensorZ\x16\n\x06pclass\x12\x0c\n\n\x08\x08\x12\x06\n\x00\n\x02\x08\x01Z\x13\n\x03sex\x12\x0c\n\n\x08\x08\x12\x06\n\x00\n\x02\x08\x01Z\x13\n\x03age\x12\x0c\n\n\x08\x01\x12\x06\n\x00\n\x02\x08\x01Z\x14\n\x04fare\x12\x0c\n\n\x08\x01\x12\x06\n\x00\n\x02\x08\x01Z\x18\n\x08embarked\x12\x0c\n\n\x08\x08\x12\x06\n\x00\n\x02\x08\x01b\x0b\n\tvariable1B\x04\n\x00\x10\x0bB\x0e\n\nai.onnx.ml\x10\x01'
Let’s compute the numerical features.
numerical features [[ 1.8514425 -0.10388696]]
We do the same for the textual features.
print(model_onnx)
text_onnx = select_model_inputs_outputs(model_onnx, "variable2")
save_onnx_model(text_onnx, "pipeline_titanic_textual.onnx")
sess = rt.InferenceSession(
"pipeline_titanic_textual.onnx", providers=["CPUExecutionProvider"]
)
numT = sess.run(None, inputs)
print("textual features", numT[0][:1])
ir_version: 7
producer_name: "skl2onnx"
producer_version: "1.20.0"
domain: "ai.onnx"
model_version: 0
doc_string: ""
graph {
node {
input: "age"
input: "fare"
output: "merged_columns"
name: "Concat"
op_type: "Concat"
attribute {
name: "axis"
i: 1
type: INT
}
domain: ""
}
node {
input: "embarked"
output: "embarkedout"
name: "OneHotEncoder"
op_type: "OneHotEncoder"
attribute {
name: "cats_strings"
strings: "C"
strings: "Q"
strings: "S"
strings: "nan"
type: STRINGS
}
attribute {
name: "zeros"
i: 1
type: INT
}
domain: "ai.onnx.ml"
}
node {
input: "sex"
output: "sexout"
name: "OneHotEncoder1"
op_type: "OneHotEncoder"
attribute {
name: "cats_strings"
strings: "female"
strings: "male"
type: STRINGS
}
attribute {
name: "zeros"
i: 1
type: INT
}
domain: "ai.onnx.ml"
}
node {
input: "pclass"
output: "pclassout"
name: "OneHotEncoder2"
op_type: "OneHotEncoder"
attribute {
name: "cats_strings"
strings: "1"
strings: "2"
strings: "3"
type: STRINGS
}
attribute {
name: "zeros"
i: 1
type: INT
}
domain: "ai.onnx.ml"
}
node {
input: "embarkedout"
input: "sexout"
input: "pclassout"
output: "concat_result"
name: "Concat1"
op_type: "Concat"
attribute {
name: "axis"
i: -1
type: INT
}
domain: ""
}
node {
input: "merged_columns"
output: "variable"
name: "Imputer"
op_type: "Imputer"
attribute {
name: "imputed_value_floats"
floats: 28
floats: 14.4542
type: FLOATS
}
attribute {
name: "replaced_value_float"
f: nan
type: FLOAT
}
domain: "ai.onnx.ml"
}
node {
input: "concat_result"
input: "shape_tensor"
output: "variable2"
name: "Reshape"
op_type: "Reshape"
domain: ""
}
node {
input: "variable"
output: "variable1"
name: "Scaler"
op_type: "Scaler"
attribute {
name: "offset"
floats: 29.3627033
floats: 32.6596565
type: FLOATS
}
attribute {
name: "scale"
floats: 0.0783271641
floats: 0.0199251696
type: FLOATS
}
domain: "ai.onnx.ml"
}
node {
input: "variable1"
input: "variable2"
output: "transformed_column"
name: "Concat2"
op_type: "Concat"
attribute {
name: "axis"
i: 1
type: INT
}
domain: ""
}
node {
input: "transformed_column"
output: "label"
output: "probabilities"
name: "LinearClassifier"
op_type: "LinearClassifier"
attribute {
name: "classlabels_ints"
ints: 0
ints: 1
type: INTS
}
attribute {
name: "coefficients"
floats: 0.416974306
floats: -0.105049103
floats: -0.160144851
floats: -0.0333919786
floats: 0.396314472
floats: -0.267065287
floats: -1.28249395
floats: 1.21820629
floats: -0.905067086
floats: -0.0627118871
floats: 0.903491378
floats: -0.416974306
floats: 0.105049103
floats: 0.160144851
floats: 0.0333919786
floats: -0.396314472
floats: 0.267065287
floats: 1.28249395
floats: -1.21820629
floats: 0.905067086
floats: 0.0627118871
floats: -0.903491378
type: FLOATS
}
attribute {
name: "intercepts"
floats: -0.124516703
floats: 0.124516703
type: FLOATS
}
attribute {
name: "multi_class"
i: 0
type: INT
}
attribute {
name: "post_transform"
s: "LOGISTIC"
type: STRING
}
domain: "ai.onnx.ml"
}
node {
input: "label"
output: "output_label"
name: "Cast"
op_type: "Cast"
attribute {
name: "to"
i: 7
type: INT
}
domain: ""
}
node {
input: "probabilities"
output: "output_probability"
name: "ZipMap"
op_type: "ZipMap"
attribute {
name: "classlabels_int64s"
ints: 0
ints: 1
type: INTS
}
domain: "ai.onnx.ml"
}
name: "pipeline_titanic"
initializer {
dims: 2
data_type: 7
int64_data: -1
int64_data: 9
name: "shape_tensor"
}
input {
name: "pclass"
type {
tensor_type {
elem_type: 8
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "sex"
type {
tensor_type {
elem_type: 8
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "age"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "fare"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "embarked"
type {
tensor_type {
elem_type: 8
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
output {
name: "output_label"
type {
tensor_type {
elem_type: 7
shape {
dim {
}
}
}
}
}
output {
name: "output_probability"
type {
sequence_type {
elem_type {
map_type {
key_type: 7
value_type {
tensor_type {
elem_type: 1
}
}
}
}
}
}
}
}
opset_import {
domain: ""
version: 11
}
opset_import {
domain: "ai.onnx.ml"
version: 1
}
textual features [[1. 0. 0. 0. 1. 0. 1. 0. 0.]]
Display the sub-ONNX graph¶
Finally, let’s see both subgraphs. First, numerical pipeline.
pydot_graph = GetPydotGraph(
num_onnx.graph,
name=num_onnx.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("pipeline_titanic_num.dot")
os.system("dot -O -Gdpi=300 -Tpng pipeline_titanic_num.dot")
image = plt.imread("pipeline_titanic_num.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
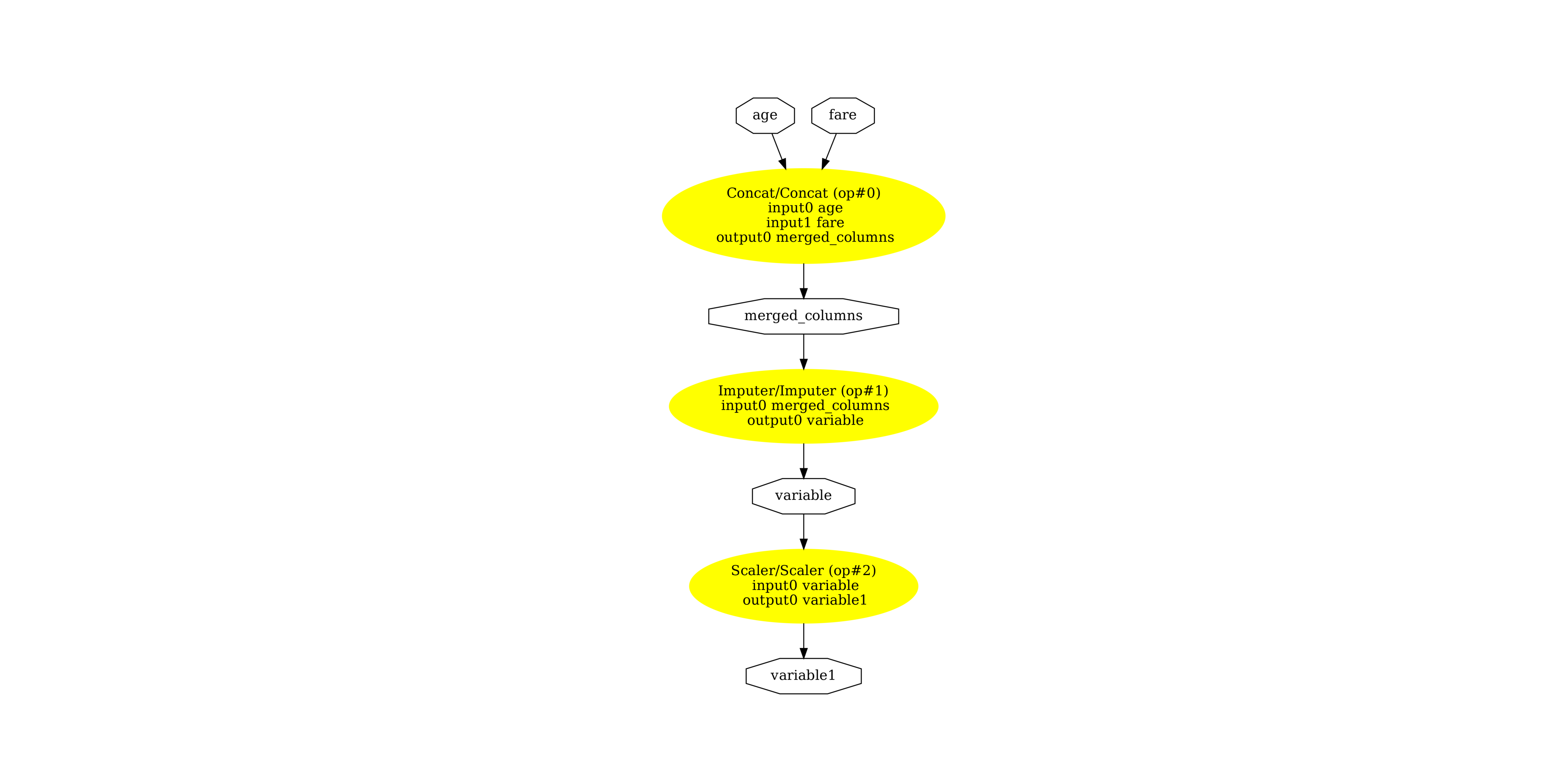
(np.float64(-0.5), np.float64(1229.5), np.float64(2558.5), np.float64(-0.5))
Then textual pipeline.
pydot_graph = GetPydotGraph(
text_onnx.graph,
name=text_onnx.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("pipeline_titanic_text.dot")
os.system("dot -O -Gdpi=300 -Tpng pipeline_titanic_text.dot")
image = plt.imread("pipeline_titanic_text.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
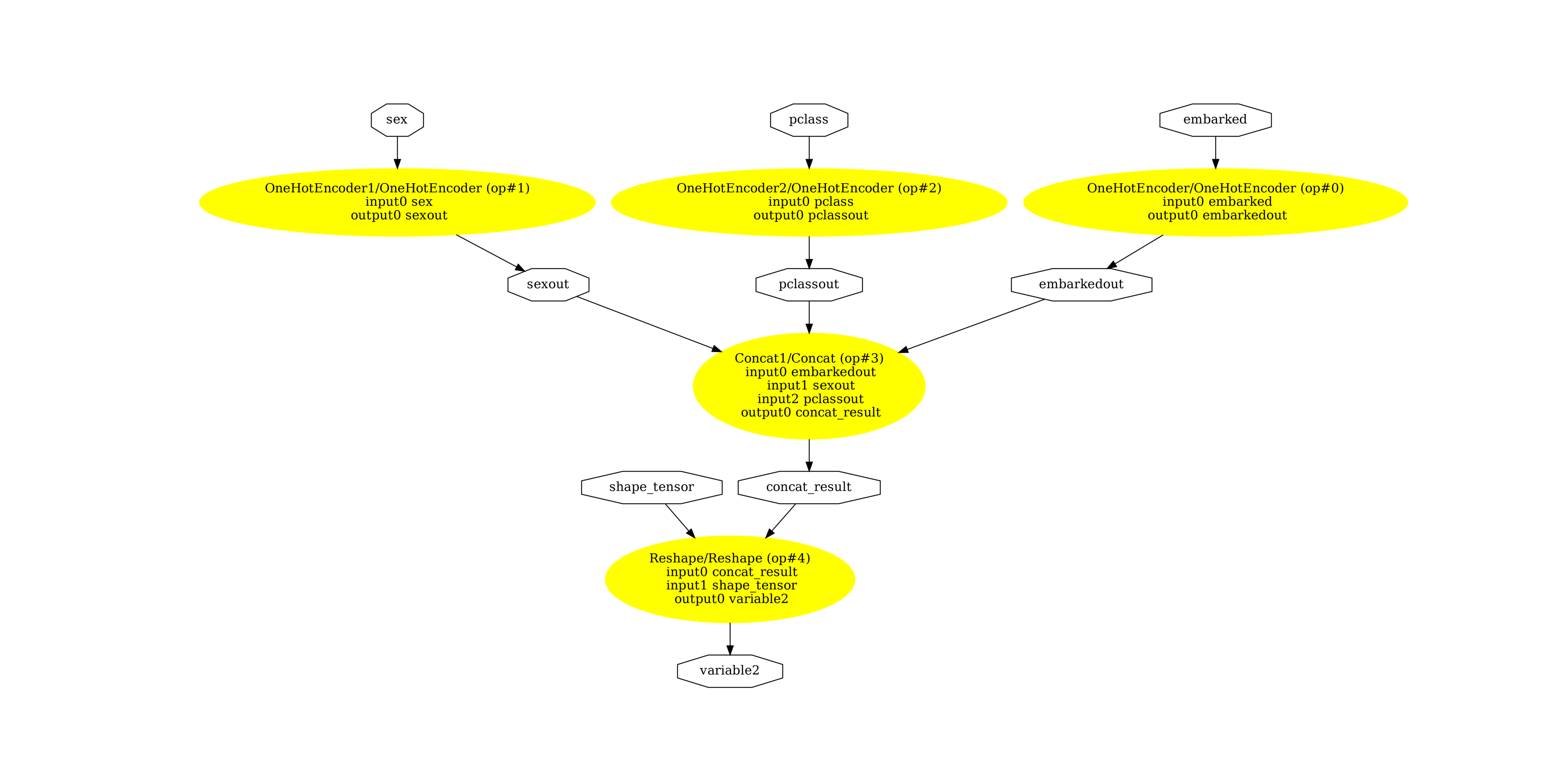
(np.float64(-0.5), np.float64(5630.5), np.float64(2735.5), np.float64(-0.5))
Versions used for this example
print("numpy:", numpy.__version__)
print("scikit-learn:", sklearn.__version__)
print("onnx: ", onnx.__version__)
print("onnxruntime: ", rt.__version__)
print("skl2onnx: ", skl2onnx.__version__)
numpy: 2.4.1
scikit-learn: 1.8.0
onnx: 1.21.0
onnxruntime: 1.24.0
skl2onnx: 1.20.0
Total running time of the script: (0 minutes 3.221 seconds)