Convert a pipeline¶
skl2onnx converts any machine learning pipeline into an ONNX pipeline. Every transformer or predictor is converted into one or multiple nodes in the ONNX graph. Any ONNX backend can then use this graph to compute equivalent outputs for the same inputs.
Convert complex pipelines¶
scikit-learn introduced ColumnTransformer, useful for building complex pipelines such as the following one:
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.decomposition import TruncatedSVD
from sklearn.compose import ColumnTransformer
numeric_features = [0, 1, 2] # ["vA", "vB", "vC"]
categorical_features = [3, 4] # ["vcat", "vcat2"]
classifier = LogisticRegression(C=0.01, class_weight=dict(zip([False, True], [0.2, 0.8])),
n_jobs=1, max_iter=10, solver='lbfgs', tol=1e-3)
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(sparse_output=True, handle_unknown='ignore')),
('tsvd', TruncatedSVD(n_components=1, algorithm='arpack', tol=1e-4))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
model = Pipeline(steps=[
('precprocessor', preprocessor),
('classifier', classifier)
])
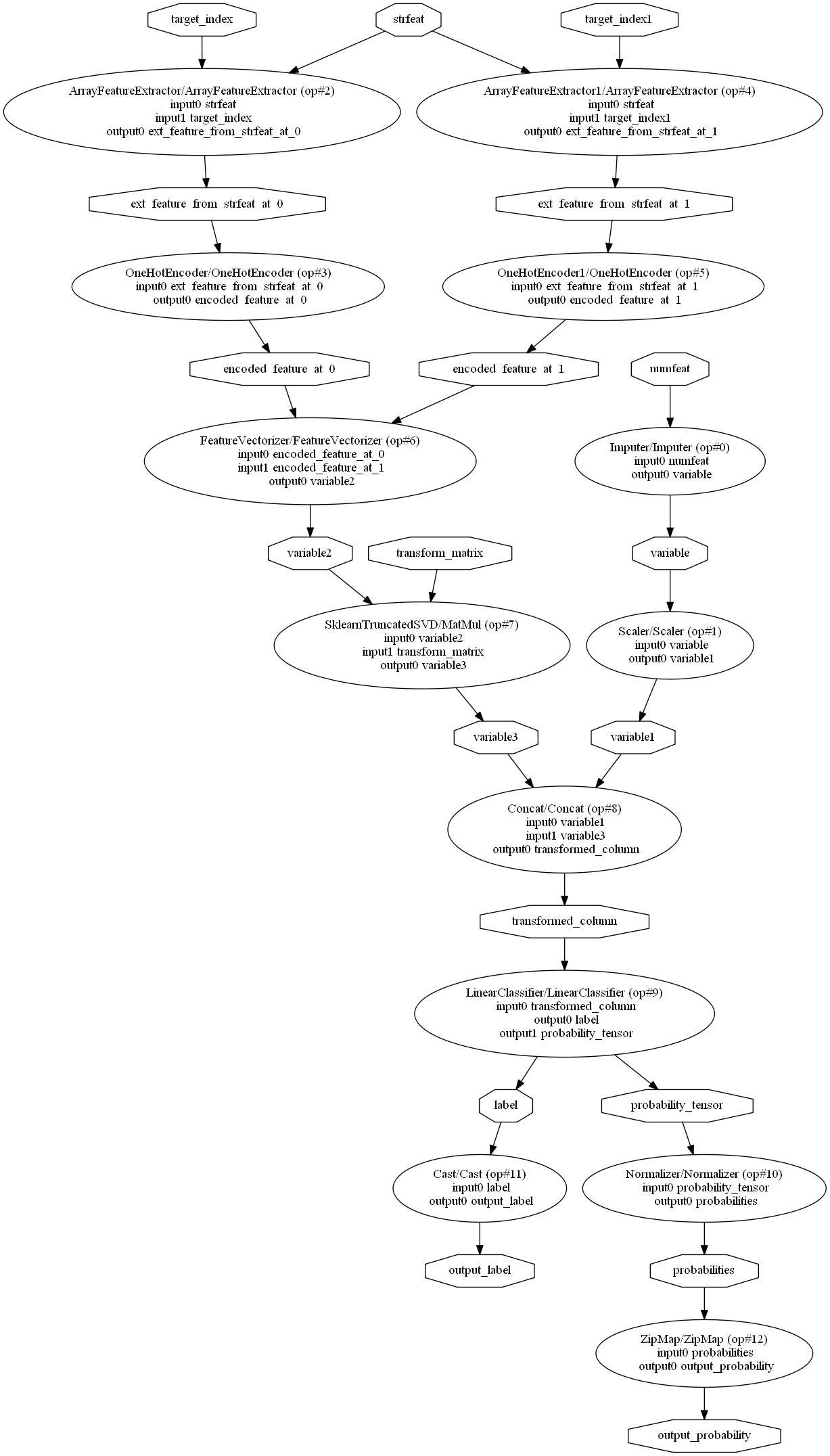
Which we can represent as:
Once fitted, the model is converted into ONNX:
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType, StringTensorType
initial_type = [('numfeat', FloatTensorType([None, 3])),
('strfeat', StringTensorType([None, 2]))]
model_onnx = convert_sklearn(model, initial_types=initial_type)
Note
The error AttributeError: 'ColumnTransformer' object has no attribute 'transformers_'
means the model was not trained. The converter tries to access an attribute
created by method fit.
It can be represented as a DOT graph:
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
pydot_graph = GetPydotGraph(model_onnx.graph, name=model_onnx.graph.name, rankdir="TP",
node_producer=GetOpNodeProducer("docstring"))
pydot_graph.write_dot("graph.dot")
import os
os.system('dot -O -Tpng graph.dot'
Parser, shape calculator, converter¶
Three kinds of functions are involved in the conversion of a scikit-pipeline. Each of them is called in the following order:
parser(scope, model, inputs, custom_parser): The parser builds the expected outputs of a model. As the resulting graph must contain unique names, scope contains all names already given. model is the model to convert. inputs are the inputs the model receives in the ONNX graph. It is a list of
Variable. custom_parsers contains a map{model type: parser}which extends the default list of parsers. The parser defines default outputs for standard machine learned problems. The shape calculator changes the shapes and types for each of them depending on the model and is called after all outputs are defined (topology). This step defines the number of outputs and their types for every node and sets them to a default shape[None, None]which the output node has one row and no known columns yet.shape_calculator(model): The shape calculator changes the shape of the outputs created by the parser. Once this function returned its results, the graph structure is fully defined and cannot be changed. The shape calculator should not change types. Many runtimes are implemented in C++ and do not support implicit casts. A change of type might make the runtime fail due to a type mismatch between two consecutive nodes produced by two different converters.
converter(scope, operator, container): The converter converts the transformers or predictors into ONNX nodes. Each node can be an ONNX operator or ML operator or custom ONNX operators.
As sklearn-onnx may convert pipelines with model coming from other libraries,
the library must handle parsers, shape calculators or converters coming
from other packages. This can be done in two ways. The first one
consists of calling function convert_sklearn
by mapping the model type to a specific parser, a specific shape calculator
or a specific converter. It is possible to avoid these specifications
by registering the new parser or shape calculator or converter
with one of the two functions
update_registered_converter,
update_registered_parser.
One example follows.
New converters in a pipeline¶
Many libraries implement the scikit-learn API and their models can
be included in scikit-learn pipelines. However, sklearn-onnx cannot
convert a pipeline which includes a model such as XGBoost or LightGBM
if it does not know the corresponding converters: it needs to be registered.
That’s the purpose of the function skl2onnx.update_registered_converter().
The following example shows how to register a new converter or
update an existing one. Four elements are registered:
the model class
an alias, usually the class name prefixed by the library name
a shape calculator which computes the type and shape of the expected outputs
a model converter
The following lines shows what these four elements are for a random forest:
from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes
from skl2onnx.operator_converters.RandomForest import convert_sklearn_random_forest_classifier
from skl2onnx import update_registered_converter
update_registered_converter(SGDClassifier, 'SklearnLinearClassifier',
calculate_linear_classifier_output_shapes,
convert_sklearn_random_forest_classifier)
See Convert a pipeline with a LightGBM classifier for a complete example with a LightGBM model.
Titanic example¶
The first example was a simplified pipeline coming from scikit-learn’s documentation: Column Transformer with Mixed Types. The full story is available in a runnable example: Convert a pipeline with ColumnTransformer which also shows some mistakes that a user could come across when trying to convert a pipeline.
Parameterize the conversion¶
Most of the converters do not require specific options to convert a scikit-learn model and produce the same results. However, in some cases, the conversion cannot produce a model which returns the exact same results. The user may want to optimize the conversion by giving the converter additional information, even if the model to convert is included in a pipeline. That why the option mechanism was implemented: Converters with options.
Investigate discrepencies¶
A wrong converter may introduce discrepancies
in a converted pipeline but it is not always easy to
isolate the source of the differences. The function
collect_intermediate_steps
may be used to investigate each component independently.
The following piece of code is taken from unit test
test_investigate.py and converts
a pipeline and each of its components independently:
import numpy
from numpy.testing import assert_almost_equal
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import onnxruntime
from skl2onnx.helpers import collect_intermediate_steps, compare_objects
from skl2onnx.common.data_types import FloatTensorType
# Let's fit a model.
data = numpy.array([[0, 0], [0, 0], [2, 1], [2, 1]],
dtype=numpy.float32)
model = Pipeline([("scaler1", StandardScaler()),
("scaler2", StandardScaler())])
model.fit(data)
# Convert and collect every operator in a pipeline
# and modifies the current pipeline to keep
# intermediate inputs and outputs when method
# predict or transform is called.
operators = collect_intermediate_steps(model, "pipeline",
[("input",
FloatTensorType([None, 2]))])
# Method and transform is called.
model.transform(data)
# Loop on every operator.
for op in operators:
# The ONNX for this operator.
onnx_step = op['onnx_step']
# Use onnxruntime to compute ONNX outputs
sess = onnxruntime.InferenceSession(onnx_step.SerializeToString(),
providers=["CPUExecutionProvider"])
# Let's use the initial data as the ONNX model
# contains all nodes from the first inputs to this node.
onnx_outputs = sess.run(None, {'input': data})
onnx_output = onnx_outputs[0]
skl_outputs = op['model']._debug.outputs['transform']
# Compares the outputs between scikit-learn and onnxruntime.
assert_almost_equal(onnx_output, skl_outputs)
# A function which is able to deal with different types.
compare_objects(onnx_output, skl_outputs)
Investigate missing converters¶
Many converters can be missing before converting a pipeline.
Exception MissingShapeCalculator is
raised when the first missing one is found.
The previous snippet of code can be modified to find all of
them.
import numpy
from numpy.testing import assert_almost_equal
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import onnxruntime
from skl2onnx.common.data_types import guess_data_type
from skl2onnx.common.exceptions import MissingShapeCalculator
from skl2onnx.helpers import collect_intermediate_steps, compare_objects, enumerate_pipeline_models
from skl2onnx.helpers.investigate import _alter_model_for_debugging
from skl2onnx import convert_sklearn
class MyScaler(StandardScaler):
pass
# Let's fit a model.
data = numpy.array([[0, 0], [0, 0], [2, 1], [2, 1]],
dtype=numpy.float32)
model = Pipeline([("scaler1", StandardScaler()),
("scaler2", StandardScaler()),
("scaler3", MyScaler()),
])
model.fit(data)
# This function alters the pipeline, every time
# methods transform or predict are used, inputs and outputs
# are stored in every operator.
_alter_model_for_debugging(model, recursive=True)
# Let's use the pipeline and keep intermediate
# inputs and outputs.
model.transform(data)
# Let's get the list of all operators to convert
# and independently process them.
all_models = list(enumerate_pipeline_models(model))
# Loop on every operator.
for ind, op, last in all_models:
if ind == (0,):
# whole pipeline
continue
# The dump input data for this operator.
data_in = op._debug.inputs['transform']
# Let's infer some initial shape.
t = guess_data_type(data_in)
# Let's convert.
try:
onnx_step = convert_sklearn(op, initial_types=t)
except MissingShapeCalculator as e:
if "MyScaler" in str(e):
print(e)
continue
raise
# If it does not fail, let's compare the ONNX outputs with
# the original operator.
sess = onnxruntime.InferenceSession(onnx_step.SerializeToString(),
providers=["CPUExecutionProvider"])
onnx_outputs = sess.run(None, {'input': data_in})
onnx_output = onnx_outputs[0]
skl_outputs = op._debug.outputs['transform']
assert_almost_equal(onnx_output, skl_outputs)
compare_objects(onnx_output, skl_outputs)