Note
Go to the end to download the full example code.
Convert a pipeline with a LightGbm model¶
sklearn-onnx only converts scikit-learn models into ONNX but many libraries implement scikit-learn API so that their models can be included in a scikit-learn pipeline. This example considers a pipeline including a LightGbm model. sklearn-onnx can convert the whole pipeline as long as it knows the converter associated to a LGBMClassifier. Let’s see how to do it.
Train a LightGBM classifier¶
import lightgbm
import onnxmltools
import skl2onnx
import onnx
import sklearn
import matplotlib.pyplot as plt
import os
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
import onnxruntime as rt
from onnxruntime.capi.onnxruntime_pybind11_state import Fail as OrtFail
from skl2onnx import convert_sklearn, update_registered_converter
from skl2onnx.common.shape_calculator import (
calculate_linear_classifier_output_shapes,
)
from onnxmltools.convert.lightgbm.operator_converters.LightGbm import (
convert_lightgbm,
)
import onnxmltools.convert.common.data_types
from skl2onnx.common.data_types import FloatTensorType
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from lightgbm import LGBMClassifier
data = load_iris()
X = data.data[:, :2]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline(
[("scaler", StandardScaler()), ("lgbm", LGBMClassifier(n_estimators=3))]
)
pipe.fit(X, y)
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.003343 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 47
[LightGBM] [Info] Number of data points in the train set: 150, number of used features: 2
[LightGBM] [Info] Start training from score -1.098612
[LightGBM] [Info] Start training from score -1.098612
[LightGBM] [Info] Start training from score -1.098612
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Register the converter for LGBMClassifier¶
The converter is implemented in onnxmltools: onnxmltools…LightGbm.py. and the shape calculator: onnxmltools…Classifier.py.
Then we import the converter and shape calculator.
Let’s register the new converter.
update_registered_converter(
LGBMClassifier,
"LightGbmLGBMClassifier",
calculate_linear_classifier_output_shapes,
convert_lightgbm,
options={"nocl": [True, False], "zipmap": [True, False, "columns"]},
)
Convert again¶
model_onnx = convert_sklearn(
pipe,
"pipeline_lightgbm",
[("input", FloatTensorType([None, 2]))],
target_opset={"": 12, "ai.onnx.ml": 2},
)
# And save.
with open("pipeline_lightgbm.onnx", "wb") as f:
f.write(model_onnx.SerializeToString())
Compare the predictions¶
Predictions with LightGbm.
print("predict", pipe.predict(X[:5]))
print("predict_proba", pipe.predict_proba(X[:1]))
/home/xadupre/vv/this312/lib/python3.12/site-packages/sklearn/utils/validation.py:2691: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
predict [1 1 0 2 1]
/home/xadupre/vv/this312/lib/python3.12/site-packages/sklearn/utils/validation.py:2691: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
predict_proba [[0.23875517 0.43192247 0.32932236]]
Predictions with onnxruntime.
try:
sess = rt.InferenceSession(
"pipeline_lightgbm.onnx", providers=["CPUExecutionProvider"]
)
except OrtFail as e:
print(e)
print("The converter requires onnxmltools>=1.7.0")
sess = None
if sess is not None:
pred_onx = sess.run(None, {"input": X[:5].astype(numpy.float32)})
print("predict", pred_onx[0])
print("predict_proba", pred_onx[1][:1])
predict [1 1 0 2 1]
predict_proba [{0: 0.23875515162944794, 1: 0.43192246556282043, 2: 0.32932236790657043}]
Display the ONNX graph¶
pydot_graph = GetPydotGraph(
model_onnx.graph,
name=model_onnx.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("pipeline.dot")
os.system("dot -O -Gdpi=300 -Tpng pipeline.dot")
image = plt.imread("pipeline.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
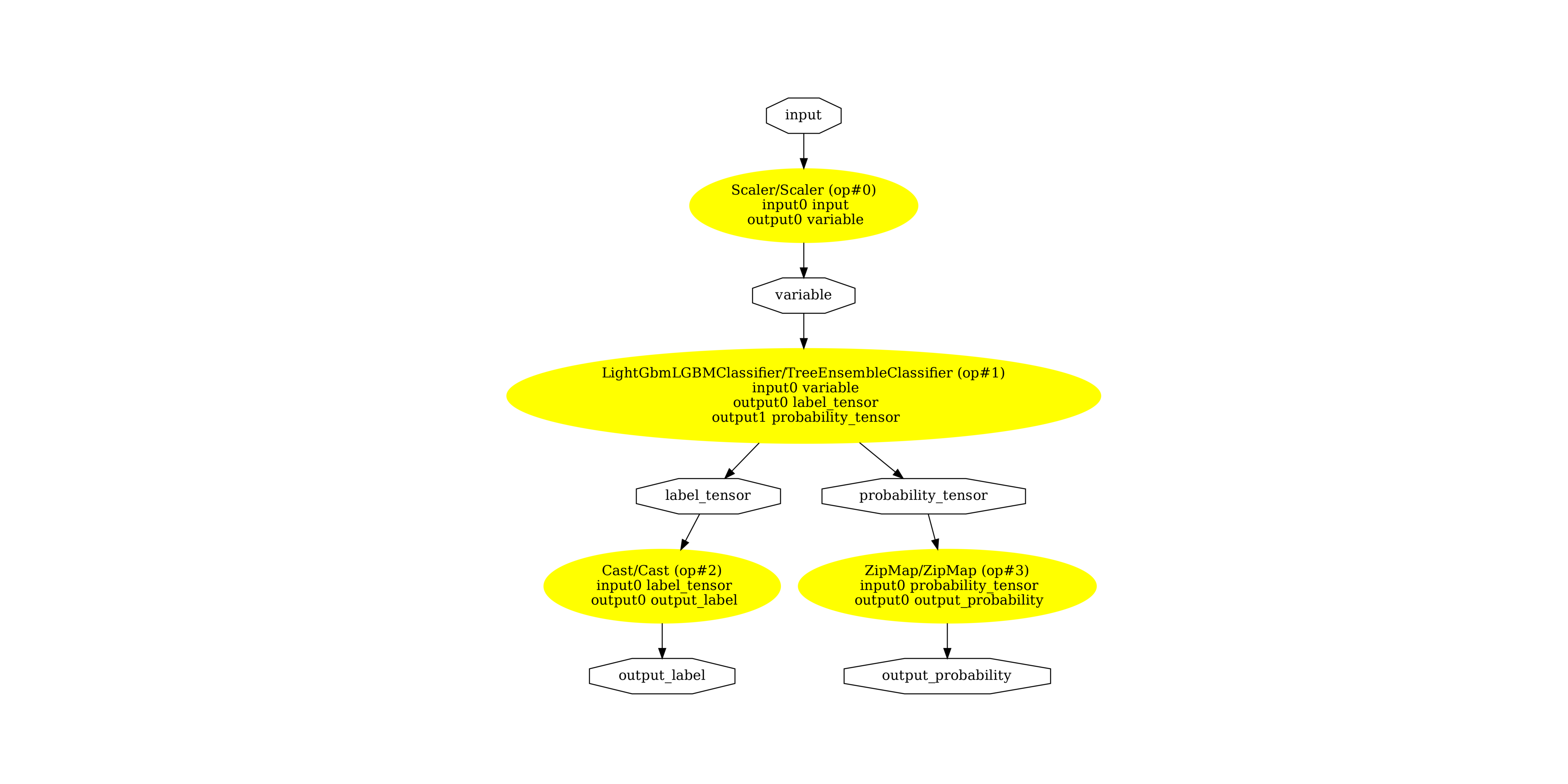
(np.float64(-0.5), np.float64(2549.5), np.float64(2558.5), np.float64(-0.5))
Versions used for this example
print("numpy:", numpy.__version__)
print("scikit-learn:", sklearn.__version__)
print("onnx: ", onnx.__version__)
print("onnxruntime: ", rt.__version__)
print("skl2onnx: ", skl2onnx.__version__)
print("onnxmltools: ", onnxmltools.__version__)
print("lightgbm: ", lightgbm.__version__)
numpy: 2.4.1
scikit-learn: 1.8.0
onnx: 1.21.0
onnxruntime: 1.24.0
skl2onnx: 1.20.0
onnxmltools: 1.16.0
lightgbm: 4.6.0
Total running time of the script: (0 minutes 1.383 seconds)